简单的路由表查找程序
文章目录
在Linux操作系统中,内核中有一个路由表,它包含若干条路由记录,这些记录由子网IP、子网掩码、网关IP和接口名等组成,这些信息用于将数据包转发到其他子网或者连接到互联网;本文介绍了当需要转发数据包时,Linux内核查找路由表的基本算法,并用程序模拟了这个过程,附有完整的源代码。本文对网络编程的初学者难度不大。
当我们在Linux系统下发送一个报文时,Linux需要确定路由,也就是将这个报文转发到哪个网络接口下的哪个设备上去,一个连接在网络上的Linux系统至少有两个网络接口,一个是网卡(有线或者无线网卡),一个loopback,Linux从报文中的IP报头中获得目的IP地址,以这个目的IP地址为依据从系统内部的路由表中找到一条最适合的路由,然后将报文转发到这个路由上,在查找路由表的过程中会使用一个叫做 最长前缀匹配(Longest Prefix Match) 的算法来确定路由;本文将简要介绍Linux系统中的路由表、路由策略以及路由决策的过程,介绍**最长前缀匹配(Longest Prefix Match)**算法,并提供一个完整的源代码来模拟这个算法在路由查找中的应用。
1. 路由表
- Linux系统的路由表
-
使用命令
cat /etc/iproute2/rt_tables看一下当前系统中有那些路由表; -
下面是在我的机器上的执行结果
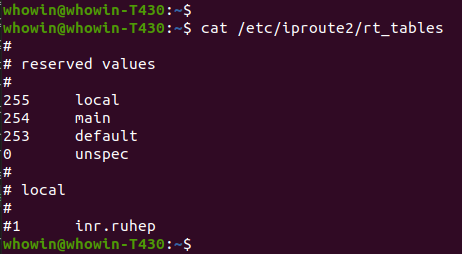
-
每个路由表除了有个名称外还有一个ID号,就是上面显示的 255、254、253 和 0;
-
可以使用命令
ip route show table <table id>/<table name>显示一个路由表; -
通常,一台机器上至少有四个路由表
- 0号路由表(unspec),由系统保留
- 253号表(default),默认路由表
- 254号表(main),主路由表,这个是主要使用的,用户可以设置
- 255号表(local),本地路由表,存储本地接口地址、广播地址、NAT地址,由系统维护,用户不能更改。
-
尽管有4个路由表,但有的表可以是空的,比如在我的机器上,默认路由表就是空的
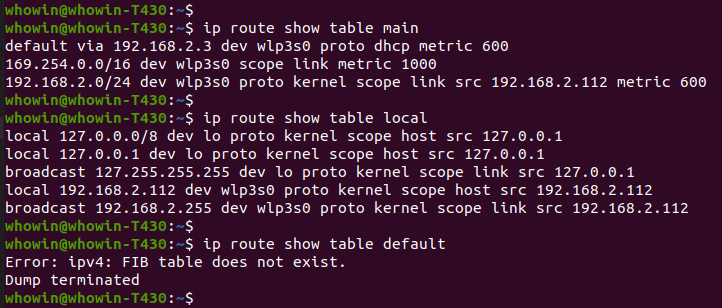
- 我的另一篇文章《linux下使用netlink获取gateway的IP地址》中,程序中使用netlink获取了内核路由表,在程序中解析内核发回的信息时,使用了宏 RT_TABLE_MAIN 就是路由表的ID号,RT_TABLE_MAIN 显然指的是主路由表(main),所以它的实际值是 254;
- Linux系统的路由策略
-
Linux系统有一个路由策略数据库,Routing Policy Database,简称 RPDB
-
使用命令
ip rule list或者命令ip rule show可以显示当前系统中的RPDB; -
下面是在我的机器上的执行结果
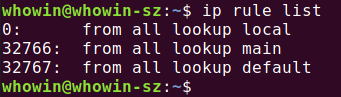
- 可以看到,我的系统RPDB中有三条路由规则,这也是Linux启动时设置的默认规则,前面的数字表示优先级,0 是最高优先级
- rule 0:查询local路由表(ID 255),查找与目的地址匹配的路由,rule 0非常特殊,不能被删除或者覆盖;
- rule 32766:查询main路由表(ID 254),该表是最常用的表,通常main路由表中有一个默认路由,如果没有更具体的路由,将匹配这个默认路由,系统管理员可以删除或者使用另外的规则覆盖这条规则;
- rule 32767:查询default路由表(ID 253),该表目前是一个空表,为今后的路由处理保留,前面的策略没有匹配到的数据包,系统使用这个策略进行处理,这个规则也可以删除。
- 由此可以看到,local路由表的优先级要高于main路由表。
3. 路由查找过程
- 基于前面对 RPDB 和多路由表的简单介绍,可以简单了解内核查找路由的过程;
- 在需要确定一个目的IP地址的路由时,Linux内核首先在路由缓存(routing cache)中查找,路由缓存是一个哈希表,用于快速查询最近使用过的路由,如果在路由缓存中找到路由,则使用该路由转发报文;
- 如果在路由缓存中没有找到路由,Linux内核将开始按照优先级遍历RPDB中的策略,对于RPDB中的每个匹配项,内核将使用最长前缀匹配算法在指定的路由表中查找目的IP地址的匹配路由,如果找不到匹配的路由,内核将转到RPDB中的下一个规则,直到找到匹配项,或者查找失败;
4. 最长前缀匹配(Longest Prefix Match)算法
-
命令
route -n可以用比较整齐的方式显示主路由表(main)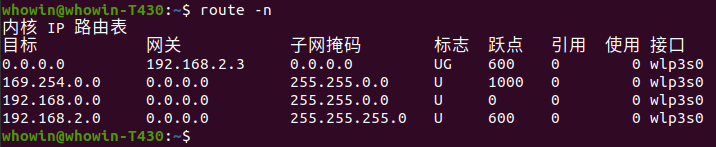
-
可以看到一个路由项有:子网IP、网关、子网掩码、网络接口等,当给定一个目的IP,比如为:192.168.2.114,与路由表中第3和第4条都匹配,那么如何确定匹配路由呢?
-
这个最长前缀匹配的算法就是解决这个匹配问题的,这个算法说的是,当遇到上面这种问题(即目的IP匹配多条路由)时,选择子网掩码最长的那个匹配项,上面这个问题,第3条路由的子网掩码为:255.255.0.0,长度为16位(255位8个二进制的1),第4条路由的子网掩码为255.255.255.0,长度为24位,所以应该匹配路由表中的第4项;
-
我们把上面的例子说的再仔细一点

- 尽管目的地址192.168.2.114也与第1条路由192.168.0.0匹配,但只匹配了16位(图示蓝色部分),而与第2条路由匹配了24位(图示红色部分),按照最长前缀匹配规则,应与第2条路由匹配;
- 所谓匹配指的是IP地址与路由的子网掩码做"与"操作后,与原来IP仍然相同的位数,192.168.2.114与255.255.0.0做"与"操作后成为192.168.0.0,只有前面的192.168与原IP地址相同,我们称之为匹配了16位。
5. 最长前缀匹配的具体实现
-
尽管这个算法很简单,但在具体实现中并不会真的去拿目的IP与和路由表中的每条路由去比较,看看匹配多少位,然后取一条位数最多的路由,这样做显得太笨了一点;
-
下面这段程序对最长前缀匹配做了一个简单的实现,文件routing.txt将用于模拟路由表,程序会把这个文件读入并生成一个路由表,我们可以按照格式编辑这个文件以使其可以模拟我们希望看到的路由情况;
-
文件routing.txt格式说明
- 第一行为表头,说明每一列的含义
- 每行一条路由,每条路由只取:接口名称、子网、网关和子网掩码四个字段,字段间使用’,‘分隔,各字段允许前后有空格
-
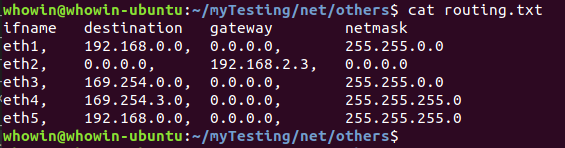
routing.txt内容
1 2 3 4 5 6ifname destination gateway netmask eth1, 192.168.0.0, 0.0.0.0, 255.255.0.0 eth2, 0.0.0.0, 192.168.2.3, 0.0.0.0 eth3, 169.254.0.0, 0.0.0.0, 255.255.0.0 eth4, 169.254.3.0, 0.0.0.0, 255.255.255.0 eth5, 192.168.0.0, 0.0.0.0, 255.255.255.0- 在路由表中,gateway为0.0.0.0表示不需要经过网关;destination为0.0.0.0表示任意IP地址;
- 当netmask为0.0.0.0而destination也为0.0.0.0时,任何IP地址与netmask做"与"操作后都将与destination匹配。
-
下面源程序中,最长前缀匹配的执行步骤
- 读取文件routing.txt作为路由表,并为路由表建立路由链表,链表的每个节点表示一条路由;
- 路由读入内存时,将所有IP和子网掩码转换成32bit整数(网络字节序,big-endian)存放;
- 将路由按照子网IP(主机字节序,little-endian)进行逆排序(数值大的排在前面),如果两个子网IP相同,则子网掩码(主机字节序,little-endian)大的排在前面;
- 从命令行读入要查找路由的目的IP地址,并将其转换成32bit整数(网络字节序,big-endian)
- 从路由链表开头开始遍历链表,将目的IP地址(32bit整数),与路由的子网掩码(32bit整数)进行与操作,如果结果与该路由的子网IP相同,则认为已经匹配到路由,程序结束。
-
使用链表存放路由是因为我们并不知道路由表中有多少条路由,不好分配内存,采用链表可以读到一条路由,分配一块内存,不会因为内存分配太少导致无法把全部路由读入内存,而且遍历一个链表也很方便;
-
在链表中存放的32bit的IP都是以网络字节序存储的,这是因为当使用inet_addr()将一个"数字、点表示法"的IP地址转换成32bit整数时,结果就是网络字节序的;
-
程序中对链表做了逆排序,可以大大提高查找速度;
- 通常情况下,在Linux的主路由表中都有一条默认网关的路由,一般子网和掩码都是0.0.0.0,加上网关IP,这个路由是和所有IP地址匹配的,进行逆排序后,这条路由将排在链表的最后,当所有路由均无法匹配时,将很自然地匹配最后一条路由,不需要在遍历路由链表时因为会遇到这条路由而进行更多的判断;
- 最长前缀匹配指出,当有多条路由匹配时,应匹配子网掩码最长的路由,所以我们在进行排序时,如果遇到两条路由的子网IP相同,将把子网掩码大的(按主机字节序比较,little-endian)排在前面,这样做的好处在于,程序匹配到的第一条路由一定是子网掩码最长的路由,无需再做判断;
试想这样两条路由,
192.168.0.0/255.255.0.0和192.168.0.0/255.255.255.0,这两条路由只有子网掩码不同,第1条路由表示192.168.*.*的走这条路由,第2条路由表示192.168.0.*的走这条路由,当目的IP为192.168.0.10时,应该是要走第2条路由的,经过我们的排序后,遍历链表时最先匹配的路由一定是第2条路由,这个例子大致说明了链表排序的意义。 -
源代码,文件名:rt-lookup.c(点击文件名下载源文件)
-
实际的路由表要比我们这个复杂的多,路由决策的因素也不仅仅是所谓的’最长前缀匹配’。
欢迎订阅 『网络编程专栏』
欢迎访问我的博客:https://whowin.cn
email: hengch@163.com

文章作者 whowin
上次更新 2023-02-10